Álvaro era o mais pessimista, Alberto se ancorava na natureza e sensações físicas, Ricardo admirava a simplicidade, e Bernardo gostava de escrever sobre o cotidiano. Se esses nomes não acenderam uma faísca na sua mente, vale lembrar que eles são todos a mesma (ou o mesmo) Pessoa. O mais célebre autor da língua portuguesa é também um dos maiores criadores de heterônimos. Fernando Pessoa escrevia poemas assumindo personalidades diferentes, cada uma com suas próprias características e histórias de vida.
A maioria dos estudantes aprende a diferenciar os estilos de Álvaro Campos, Alberto Caeiro, Ricardo Reis e Bernardo Soares (este último sendo um semi-heterônimo do poeta) ainda no ensino médio. Mas será que um computador conseguiria fazer o mesmo?
Essa era a pergunta do Turing, um grupo de extensão formado por alunos da USP. Eles usaram aprendizado de máquina para criar um classificador de heterônimos do autor português. A ideia surgiu quando o grupo estudava temas relacionados ao processamento de linguagem natural, como a classificação de texto.
Aqui vale um adendo: processamento de linguagem natural é a área da Inteligência Artificial que lida com línguas humanas, como português, inglês, espanhol etc. É ela que está por trás de ferramentas como o Google Tradutor e das respostas automáticas de assistentes virtuais.
A equipe usou o banco de dados do Arquivo Pessoa, que contém todos os poemas de heterônimos do autor português. Após fazer a formatação dos textos (que às vezes chegam desorganizados), os estudantes treinaram a máquina para reconhecer palavras que fossem características de cada personalidade.
“Se a palavra ‘casa’ aparece em todos os heterônimos, ela não é um bom indicador de distinção entre eles. Mas se ‘copo’ aparece muitas vezes em um e poucas vezes em outro, então usamos essa palavra como um diferenciador entre os autores”, diz Lucas Sepeda, membro do grupo Turing que participou do projeto.
Digamos que a palavra diferencial seja mesmo “copo”. Os poemas que contém essa palavra são classificados de um lado, enquanto os que não contém são colocados de outro. O algoritmo, então, traça um plano que separa esses dois tipos de texto.
Acontece que o programa não usa apenas uma palavra para diferenciar os heterônimos, mas milhares delas. O resultado é um espaço virtual com diversas dimensões – uma para cada palavra – e um hiperplano que separa os autores. O algoritmo acerta quem é o autor do texto em 82,71% dos casos.
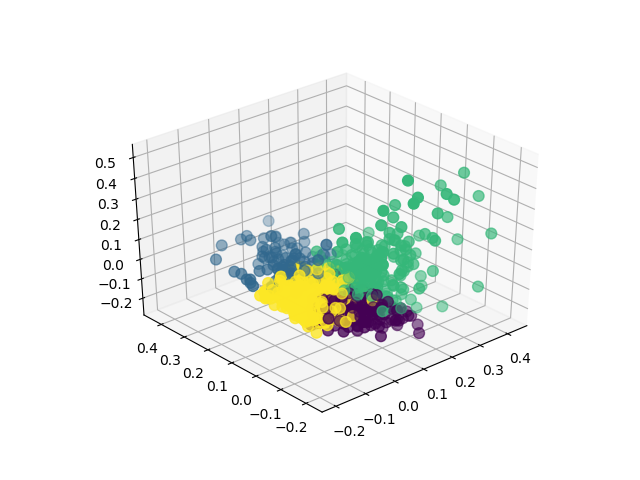
O maior desafio foi fazer uma ferramenta que funcionasse para o português – o idioma como um todo, e não apenas o autor. “Existem menos estudos e dados para desenvolver modelos em português. Com ferramentas em inglês seria mais fácil de fazer”, diz Fernando Matsumoto, membro do Turing que também participou do projeto.
O objetivo do grupo de estudos é justamente viabilizar mais ferramentas para a nossa língua. Enquanto a maior parte dos membros do grupo é composta por alunos da área de exatas, a líder da área de Processamento de Linguagem Natural, Julia Pocciotti, é estudante de linguística na Faculdade de Filosofia, Letras e Ciências Humanas da USP.
“Os nossos pilares são estudar, aplicar e disseminar a Inteligência Artificial”, diz Pocciotti. Por isso, todos os códigos de programação do grupo Turing são abertos. O classificador de heterônimos de Fernando Pessoa encontra-se disponível aqui.




Classificador usa IA para diferenciar heterônimos de Fernando Pessoa Publicado primeiro em https://super.abril.com.br/feed
Nenhum comentário:
Postar um comentário