No mundo da inteligência artificial, existem os chamados geradores texto-imagem. É um nome bem autoexplicativo: baseado na frase que o usuário digita, o sistema devolve uma imagem correspondente ao que foi escrito.
Até então, o líder no campo desse tipo de programa era o DALL-E, software criado pelo laboratório OpenAi. Agora, o Google resolveu entrar na jogada com o Imagen, anunciado na última terça (24).
O Imagen funciona da mesma forma que os outros geradores: com base em um texto, ele gera uma imagem. Na página dedicada ao programa, ele é descrito como tendo um “grau de fotorrealismo sem precedentes e uma profunda compreensão de linguagem”. De fato, basta observar as imagens divulgadas pela empresa para entender o potencial da nova ferramenta:


Segundo o Google, o Imagen produz imagens melhores do que o DALL-E. Para chegar a essa conclusão, a empresa criou uma métrica de comparação, chamada de DrawBench. Não é nada muito complexo: eles usaram o mesmo texto para criar imagens em diversos geradores. As produções foram submetidas a juízes humanos, que escolheram suas preferidas. E os resultados do Imagen foram escolhidos mais vezes do que os dos concorrentes.
Os problemas dos Imagen
Apesar dos resultados sobre o Imagen impressionarem, é preciso cautela. Afinal, as imagens divulgadas foram escolhidas a dedo para mostrar o melhor da capacidade do software – e podem não representar o resultado médio dos testes.
Outro problema do Imagen: mesmo com um gigantesco potencial artístico e criativo, o programa poderia ser usado para gerar fake news e desinformação – assim como tem acontecido com os deep fakes.
O time do Google também chama atenção para problemas causados pela base de dados do projeto. Vamos por partes: sistemas assim funcionam por meio do machine learning (“aprendizado de máquina”, em inglês). O software é exposto a uma quantidade imensa de dados (no caso dos geradores texto-imagem, textos e imagens relacionadas a eles). O programa, então, estuda esses dados para encontrar padrões (associar a palavra “bola” a imagens com diversos tipos de bola, por exemplo).
O objetivo é que, com esse aprendizado, o programa possa replicar esses padrões de acordo com a demanda do usuário. Se eu digitar “bola de futebol americano”, ele precisa não apenas entender que eu quero a imagem de uma bola, mas que é uma bola oval marrom com a costura aparente.
Para criar imagens tão complexas como as que você viu acima, o Imagen, claro, precisa de uma quantidade gigante de dados. E quanto maior esse volume, mais difícil é filtrá-lo. E é aí que está o problema: ao absorver essas informações de bancos da internet, as máquinas aprendem a carregar consigo os mesmos preconceitos e estereótipos que se espalham na rede.
“Existe o risco de que o Imagen tenha codificado estereótipos e representações prejudiciais, o que justifica nossa decisão de não liberar o Imagen para uso público,” disse a equipe do projeto em sua página oficial. Após uma avaliação preliminar, a empresa identificou “vários preconceitos e estereótipos sociais” incorporados pelo Imagen, “incluindo uma tendência em gerar imagens de pessoas com tons de pele mais claros e uma inclinação em retratar diferentes profissões de acordo com estereótipos de gênero ocidentais”.
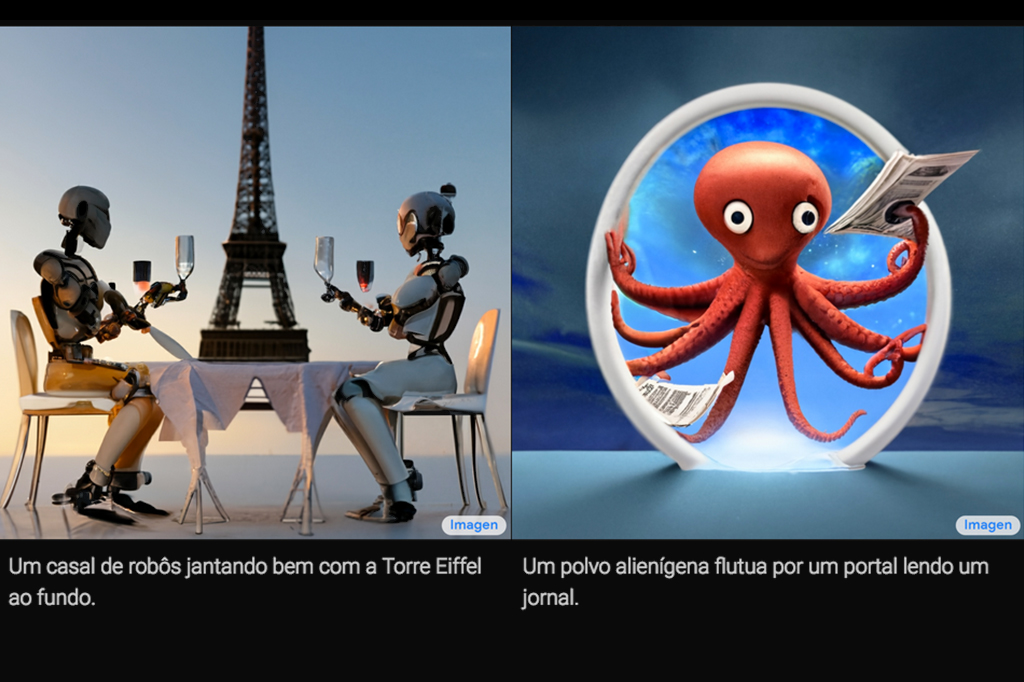
É por essas e outras que o Imagen ainda não tem previsão de lançamento para o público. O Google se comprometeu a consertar “esses desafios e limitações em trabalhos futuros”. Espera-se que, com novas atualizações, o programa se torne uma ferramenta segura para gerar imagens incríveis a partir de textos simples.
Imagen: como funciona a inteligência artificial do Google que transforma texto em imagem Publicado primeiro em https://super.abril.com.br/feed
Nenhum comentário:
Postar um comentário